Object-Relational DBMS - The Next Wave
by Michael Stonebraker
Introduction
In this paper we present a classification of the applications
that require DBMS technology and show where Relational DBMSs,
Object-oriented DBMSs and Object-Relational DBMSs fit. Our purpose
is to indicate the kinds of problems each kind of DBMS solves.
As will be seen, "one size does not fit all"; i.e. there is no DBMS
that solves all the applications we are going to discuss. Then, we
indicate why the problems addressed by Object-Relational DBMSs are
expected to become increasingly important over the remainder
of this decade. As such, it is "the next wave".
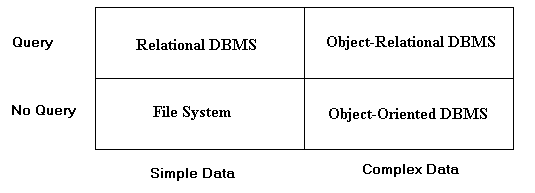
Our classification scheme makes use of the two by two matrix indicated
in Table 1.

A Classification of DBMS Applications
Table 1
Here, we show a horizontal axis with very simple data to the left
and very complex data to the right. In general, the complexity
of the data that an application must contend with can vary between
these two extremes in a continuous fashion. However, for simplicity,
we assume there are only two discrete possibilities, namely simple
data and complex data. Similarly, on the vertical axis we differentiate
whether the application requires a query capability. This can
vary between "never" and "always". Again,
there is a continuum between the two extremes; however, for simplicity
we assume there are only two discrete possibilities. These are
respectively "query" and "no query".
A user can examine an application and then place it in one of
the four boxes in Table 1 depending on its characteristics. In
order to illustrate this classification process, we explore an
application in each of these four boxes. In the process of discussing
each application, we will discuss the requirements that each has
of a DBMS and then suggest that there is a natural choice of data
manager for each of the four applications.
Lower Left Corner
Consider a standard text processing system such as Word for Windows,
Framemaker, Word Perfect, vi, or emacs. All allow the user to
open a file by name, which results in the contents of the file
being read into virtual memory on behalf of the user. Then the
user can make editing gestures that update the virtual memory
object. At intervals, the object is saved to disk storage. Finally,
when the user is finished he can close the file, thereby causing
the virtual memory copy to be stored back to the file system.
The only query made by a text editor is "get file",
and the only update is "put file". As such, this qualifies
as a "no query" application, and a text editor has no
use for SQL. In addition, a text editor is satisfied with the
data model presented by the file system, namely as an arbitrary
length sequence of characters. As such, this is a "no query
-- simple data" application and fits in the lower left hand
corner of our two by two matrix.
Two quick points should be made before proceeding. First, we
are discussing text editors and not more sophisticated groupware
products, such as Lotus Notes. In addition, we are likewise not
discussing document management systems, such as Documentum. Both
kinds of products would have to be placed independently in our two
by two matrix.
The obvious DBMS for applications in the lower left hand corner
of our matrix is the file system provided by the operating system
vendor for the hardware in question. In fact, all text editors
I know of use this primitive level of DBMS service currently,
and have no plans to move to anything more sophisticated. The
reason is quite simple: if you have no need for queries and no
need for complex data, then the service provided by the file system
is perfectly adequate. Moreover, file system invariably have
higher performance than any more sophisticated system. Hence,
if you don't need the service, then there is no need to pay for
it in terms of lower performance.
The bottom line is simple. If you have an application in the
lower left hand corner of Table 1, then you should deploy it on
top of the file system provided with your computer. As such,
we can label the lower left hand corner with "file system"
and move on to another box, namely the upper left hand corner.
Upper Left Hand Corner
We illustrate the upper left hand corner by treating a well known
example. Suppose we want to store information about each employee
in a hypothetical company, namely we wish to record the name of
the employee, his age, his salary, and his department. In addition,
we require information about the departments in this company,
namely their department name, their budget and the floor number
they are located on. The schema for this information can be captured
by the following standard SQL statements:
create table emp (
name varchar(30),
age int,
salary float,
dept varchar(20));
create table dept (
dname varchar(20),
budget float,
floor int);
Notice that the user wishes to store a collection of structured
records, each of which has attributes which are simple integers,
floats and character strings. Hence, the records utilize the
standard data types found in SQL-92. As such, we classify this
data as "simple". Users wish to ask a collection of
queries against this data such as:
Find the names of employees who are under 40 and earn more than
$40,000.
select name
from emp
where age < 40 and salary > 40000;
Find the names of employees who work on the first floor.
select name
from emp
where dept in
select dname
from dept
where floor = 1;
Find the average salary of employees in the shoe department.
select avg(salary)
from emp
where dept = 'shoe';
Hence, the inquiries that the user wishes to make are naturally
queries, and we have chosen to express them in standard SQL-92.
As such, we view this application as one in the "simple data -- query"
box. Applications in the upper left hand corner that have this
characteristic tend to be identified as "business data processing"
applications and have the following requirements:
Query Language: Requirement for SQL-89. Desirable to
also have the newer SQL-92 standard.
Client Tools: Requirement for a tool kit that allows a
programmer to set up forms for data entry and display. Tool kit
must also allow sequencing between forms through control flow
logic. Such tool kits are called fourth generation languages
(4GLs). Example 4GLs include Powerbuilder from Sybase, Windows/4GL
from Computer Associates, SQL-forms from Oracle, and products
from Easel, Gupta, and Progress. In fact, there are perhaps 75
4GLs on the market today, all offering similar capabilities.
Moreover, it is not a significant stretch to call Lotus/Notes
or Mosaic a 4GL. In addition, client tools must include a report writer,
data base design tool, performance monitor and the ability to call DBMS
services from a variety of third generation languages (e.g. C,
FORTRAN, COBOL).
Performance: Much of the business data processing marketplace
entails so-called transaction processing. Here, many simultaneous
users submit requests for DBMS services from client terminals
or PCs. The user interactions tend to be fairly simple SQL statements.
In addition, many are updates. When parallel conflicting updates
are processed by a DBMS, then the user requires a predictable
outcome. This has led to the notion of two phase locking which
ensures so-called serializiability. The user unfamiliar with
this concept is advised to consult a standard textbook on DBMSs,
such as the one by Date, Bradley or Ullman. In addition, there
is an absolute requirement to never lose the user's data, regardless
of what kind of failure might have occurred. These include disk
crashes as well as operating system failures. Providing recovery
from crashes is typically provided by utilizing write-ahead log
(WAL) technology. The user interested in this topic is also advised
to consult a standard textbook. Together, two phase locking and
a write ahead log provide transaction management; i.e. user queries
and updates are grouped into units of work called transactions.
Each transaction is atomic (i.e. it either happens completely
or not at all), serializable (i.e. appears to have happened before
or after all other parallel transactions) and durable (once committed,
its effect can never be lost).
Security: Since users put sensitive data, such as salaries,
into business data processing data bases, there is a stringent
requirement for DBMS security. As a result, the DBMS must run
in a separate address space from the client application, so that
an address space crossing occurs whenever a DBMS service request
is executed. In this way, the DBMS can run with a different user
identifier from that of any application. Moreover, actual data
files utilized in the database are specified as readable and writable
only by the DBMS. This client-server architecture, shown in Figure
1, is a requirement of upper left hand corner applications.

Standard Client Server Architecture
Figure 1
In any case, the user requires an SQL DBMS optimized for transaction
processing entailing many simultaneous users with simple commands.
A standard benchmark that typifies this sort of interaction is
TPC-A from the Transaction Processing Council. TPC-A is discussed at length
in the "The Benchmark Handbook" by Jim Gray. There
is a movement over time toward more complex transactions, and
TPC has responded with a series of "heavier" transaction
standards, respectively called TPC-B, TPC-C and TPC-D.
This set of requirements for an SQL DBMS with 4GL client tools
optimized for transaction processing is met very well by the current
relational DBMS vendors. The main ones are Oracle, Sybase
and CA-Ingres. In addition, Tandem, Hewlett-Packard and IBM also
offer relational database products.
These products differ on detailed features; however all satisfy
the above requirements. Hence, from 50,000 feet, all look very
similar. Moreover, all engage in considerable marketing hype
touting their respective wares.
For the purposes of this paper, the decision is quite simple:
if you have an application in the upper left hand corner, then
solve it using a relational DBMS.
It should be clearly noted that there are many applications in
the upper left hand corner. Collectively, the relational DBMS
market is approximately $4B per year and growing at above 25%
per year. Relational DBMS customers have an insatiable demand
for additional licenses, add-on products and consulting services.
As such, the Relational DBMS vendors are generally very healthy
companies.
The only storm cloud on the horizon is the imminent arrival of
Microsoft into this market. They now have unlimited rights to
the Sybase code line on Windows/NT and have a substantial group
in Redmond, Washington improving it. Besides having a good product,
Microsoft is committed to "PC pricing" for database
systems. As such, they are undercutting the pricing structure
of the traditional vendors, and generally causing Relational DBMS
license prices to fall. As such, look for continued erosion of
pricing in this market.
Business data processing is a large and demanding market. Vendors
have their hands full with the following kinds of tasks:
- run well on shared memory multiprocessors
- interface to every transaction monitor under the sun
- run on every hardware platform known to man
- provide a gateway to all the other vendor's DBMSs
- provide parallel execution of user queries
- solve the "32 bit barrier", i.e. run well on very
large data bases
- provide "7 times 24", i.e. never require taking
the database offline for maintenance
As such. the Relational DBMS vendors have large development staffs
busily improving their products in all of these areas.
We now turn to the right hand side of our two by two matrix, and
discuss the lower right hand corner.
Lower Right Corner
I now present a simple application which fits in the lower right
hand corner. Suppose the user is the facilities planner for a
company that has an "open floor plan", i.e. nobody gets
an office. Hence, all employees are arranged into cubicles, with
partitions separating them. An example company with an open floor
plan is Hewlett Packard. In such a company, departments grow
and shrink and employees get hired and quit. Over time, the arrangement
of employees on the physical real estate of the building becomes
suboptimal, and a global rearrangement of space is warranted.
This "garbage collection" of free space and concurrent
rearrangement of employees is our target application.
The database for this application can be expressed in the following
SQL commands:
create table employee (
name varchar(30),
space polygon,
adjacency set-of (employee));
create table floors (
number int,
asf swiss-cheese-polygon);
For each employee we wish to record his name, the current real
estate that he occupies (space) as well as the collection of employees
that he shares a common carrel wall with (adjacency). For each
floor we need to record the floor number and the assignable square
feet (asf). This quantity is the outline of the building minus
the rest rooms, elevator shafts and fire exits. As such, it is
a polygon with "holes" in it, which we term a "swiss
cheese polygon". Likewise, space is a polygon and adjacency
is a set. Obviously, this data is much more complex than the
emp and dept data previous discussed. As such, this application
is on the right hand side of Table 1.
The garbage collection application can be pseudocoded as follows:
main ()
{
read all employees;
read all floors;
compact();
write all employees;
}
Here, the program must read all employee records to ascertain
their current space as well as all floors to get their asf. The
program will build some sort of virtual memory structure for the
next step of the program. This compaction routine will then walk
this structure, perhaps many times, to generate a revised allocation
of employees into the asf on each floor. When compaction is complete,
each employee record must be rewritten with a new space allocation.
Obviously, this program reads the entirety of both data collections,
computes on this collection, and then writes one collection.
Hence, it is analogous to the text editor which read, computed
on, and then wrote a single file. Like the text editor, there
is not a query in sight. Unlike the text editor, the data is
involved in the application is rather complex. As such, we claim
this is a lower right hand corner application.
The reader might complain that this application seems quite artificial.
However, it is very representative of most electronic CAD applications.
For example, a chip design is stored on disk as a complex object,
read into main memory, compacted by an optimization program, and
then written back to persistent storage. Finding the power consumption
or timing faults have a similar structure. As such, ECAD applications
are very similar to our garbage collection application, and we
used the latter application because it is generally accessible
to laypersons and is somewhat simpler than the corresponding CAD
application.
Using a traditional file system for this application is fairly
painful. The application must manually read the employee and
floors information. However, more tedious is the requirement
of converting the data from disk format to main memory format.
If we consider the adjacency information, it is a set of employees
and might be represented on disk as a set of unique identifiers
for employees. These unique identifiers should be converted to
virtual memory pointers during the load process. Because virtual
memory pointers are transient and depend on where the data is
actually loaded in memory, they cannot be reused in subsequent
executions of the program. As such disk pointers are fundamentally
different from main memory pointers, and the load process must
convert from one to the other. Similarly when the data is written
back to disk, the adjacency information may have been changed
by the compaction routine, requiring a reverse conversion from
main memory to disk representation.
Loading, converting and then unloading and reconverting the data
is tedious effort that must be done by the person writing the
compaction routine if he is using a file system as a storage engine
for the application. A much better solution would be to support
persistent storage for the programming language in which compact
is written. For purposes of exposition, suppose this is C++. As a
result, compact would have a collection of data structures defined for
its computation. One such declaration would be:
integer I;
In a normal programming language I is a transient variable,
i.e. it has no value unless initialized by the program and its
value is lost when the program terminates. Suppose we allow persistent
variables, declared as follows:
persistent integer J;
In essence, we wish J to be persistent. Hence, its value
is automatically saved when the compaction program terminates.
This value is also automatically available when the program is
restarted the next time. With persistent variables, it becomes
the problem of the language support system to load and unload
data as well as to convert it from disk format to main memory
format and back. The person writing the compaction routine need
only write his algorithm and is freed from other details.
A persistent programming language offers the best DBMS support
for this compaction application. With such a facility, the user
can move from writing the following code:
main ()
{
read all employees;
read all floors;
compact();
write all employees;
}
to merely having to write:
main ()
{
compact();
}
A persistent programming language is fundamentally very closely
integrated with a specific language. Clearly, the persistence
system must understand the specific data declarations of the target
language. Hence, if one writes compact in COBOL, then he requires
persistent COBOL, and persistent C++ is completely useless. As
such, we require one persistence system for each language.
Notice that our application has the following DBMS requirements:
Query Language: none is required for this application.
If one is present, it serves no useful purpose.
Client Tools: the writer of compact presumably is using
some sort of programming language tool kit such as the one from
Parc Place or Next. As such, he is expecting to obtain client
tools from a programming language productivity company. Client
tools from the persistent storage company are much less critical.
Performance: the fundamental performance problem that
this application wants solved is the following. If he runs compact
on "vanilla" C++ and performs his own storage management,
then he obtains a certain performance. If he moves his compact
routine on top of a persistent language, then he wishes compact
to run no more than (say) 10 percent slower. Hence, the main
performance requirement for a persistent language is to "keep
up" with a non-persistent one.
Security: The above performance requirement is at the
root of the architecture of persistent languages. Specifically,
suppose the user executes the following command:
J = J + 1;
i.e. he increments J. If J is non-persistent,
then this statement executes in 1 microsecond or less. On the
other hand, if J is persistent, then this statement becomes
an update. If the storage system runs in a different address
space than the user program, then an address space switch must
occur to process this command. As a result, the command will
run perhaps 2-3 orders of magnitude slower than in the non-persistent
case. Such a performance hit is unacceptable to users, and this
causes the designers of persistent storage systems to execute
them in the same address space as the user program, as noted in
Figure 2.

The Architecture of Persistent Languages
Figure 2
Avoiding an address space change generates much higher performance;
however, it has one dramatic side effect. A malicious program
can use operating system read and write calls to read and write
any data that the storage system is capable of reading or writing.
Since both run in the same address space, the operating system
cannot distinguish them from a security perspective. As a result,
any user program can read and write the entire data base, by going
around the persistent storage system and dealing directly with
the operating system.
One should clearly note that storing employee salaries in such
a system would be intolerable. No database administrator could
put sensitive data in a system with no security. Designers of
persistent languages obtain very high performance by trading security.
In the lower right hand corner, this tradeoff is often acceptable.
The reader might wonder why this discussion does not apply to
Relational DBMSs. There is a crucial difference between the two
worlds. In the persistent language world, updates are very "lightweight",
i.e. they take very small amounts of time. The example update:
J = J + 1;
takes at most 1 microsecond. As such, the address space overhead
becomes a killer. In a relational world, updates are much heavier,
i.e. they require locating one or more records through a B-tree
and then modifying them. This requires a substantial path length,
leading to updates that are 2-3 orders of magnitude heavier than
in a persistent language world. For example, the following SQL
query is indicative:
select name
from emp
where age > 40;
This is the difference between expressing updates in a high level
language like SQL and a low level language like C++. With heavy
updates, the address space crossing entailed by a client-server
architecture generates some overhead; however it is not severe
enough to require modification of the client-server architecture.
Systems that are focused on providing tight integration with a
programming language, high performance for updates to persistent
variables, and little (if any) focus on SQL are available for
C++ and more recently for Smalltalk from a collection of Object-oriented
DBMS vendors, such as Objectivity, Object Design, Ontologic, Versant,
Servio, O2 and Matisse. Collectively, we will call these the
"O vendors", and will claim that they are focused on
providing the data management needs of applications in the lower
right hand corner. Collectively, they are generating about $70M
per year in revenue, and are growing at nearly 50 percent per
year. As such the O vendors collectively are nearly 2 orders
of magnitude smaller than the R vendors. As such, they represent
a niche market. For example the object-oriented data base market is nearly
one order of magnitude smaller than the Geographic Information
Systems (GIS) market.
In my opinion, DBMS choices are quite easy. If you have an application
in the lower right hand corner, then you should choose a vendor
of a persistent language for your chosen programming language.
That vendor is committed to the performance and features required
in this corner of the matrix.
The observant reader might ask "What will happen if I have
a lower right hand corner application and I run it on a relational
DBMS?" The answer is quite simple. Instead of being able
to state:
J = J + 1;
one will have to express this command in SQL to some stored data
base. Because the type system of C++ is much more elaborate than
that of SQL, the user will have to simulate the C++ type system
in SQL. This simulation is quite painful and will require the
user to manually map his C++ variables into the SQL world on reads
and writes. Moreover, he will perform a heavyweight client-server
address space crossing on most commands. As a result, the application
will be very painful and very slow. Put differently, using a
DBMS designed for one kind of application in a very different
environment will result in a disaster. The net result is that
Relational systems essentially don't work on lower right hand
corner problems.
The opposite question also bears asking "What happens if
I have an upper left hand corner problem and I run it on a Object-oriented
DBMS?". Again, the result will be pain and suffering.
Specifically, most O vendors have very limited SQL, and several
do not support updates at all from SQL. As such, the user will
have to drop into C++ to express his transactions, resulting in
a great deal more code. In addition, the products of the O vendors
are typically not optimized for support 50 or 100 concurrent updaters,
and they tend to offer very poor performance in this world. Put
differently, using a DBMS designed for one kind of application
in a very different environment will result in a disaster. The
net result is that object-oriented DBMSs don't work well on upper
left hand corner problems.
We now turn to the final box in our two by two matrix.
Upper Right Corner
We now turn to an application that is query-oriented and requires
complex data. As such, it is representative of the upper right
hand corner. The State of California Department of Water resources
(DWR) is charged with managing most of the waterways and irrigation
canals in California, as well as a collection of aqueducts, including
the massive state water project. To document their facilities,
they maintain a slide library of 35mm slides. Over time this
library has grown to 500,000 slides and is currently accessed
between 5 and 10 times per day by DWR employees and others.
The client is typically requesting a picture by content. For
example, an employee might have to give a presentation in which
he needed a picture of "the big lift", a massive pumping
station that lifts Northern California water over the Tecahappi
Mountains into Southern California. Another request might be
for a picture of San Francisco Bay at sunset, while a third might
request a picture of a reservoir whose water level was very low.
DWR has found that it is very difficult to find slides by content.
Indexing all the slides according to a predefined collection
of concepts is a prohibitively expensive job. Moreover, the concepts
in which clients are interested changes over time. For example,
low water in a reservoir was never of interest until the current
drought started 7 years ago. Similarly, endangered species are
currently a heated issue, but only in the last few years.
At the current time, they have a written caption about each slide.
One example might be:
picture of Auburn Dam taken during scaffold construction
and a fairly primitive system which can identify slides from specified
keywords. This keyword system is not operating very well because
many concepts of interest are not mentioned in the caption, and
hence cannot be retrieved.
As a result, DWR is scanning the entire slide collection into
digital form and is in the process of constructing the following
database:
create table slides (
id int,
date date,
caption document,
picture photo_CD_image);
create table landmarks (
name varchar(30),
location point);
Each slide has an identifier, the date it was taken, the caption
mentioned above, and the digitized bits in Kodak Photo-CD format.
In fact, Photo-CD format is a collection of 5 images ranging
from a 128 X 192 "thumbnail" to the full 2K X 3K color
image. At the current time, DWR has digitized about 20,000 images
and is well on their way to building a data base whose size will
be around 3 terabytes.
DWR is very interested in classifying their images electronically.
As noted above, classifying them by hand is implausible. One
of the attributes they wish to capture is the geographic location
of each slide. Their technique for accomplishing this geo-registration
involves a public domain spatial data base from the US Geologic
Survey. Specifically, they have the names of all landmarks that
appear on any topographic map of California along with the map
location of the landmark. This is the table landmarks mentioned
above. Then, they propose to examine the caption for each slide
and ascertain it contains the name of a landmark. If so, the
location of the landmark is a good guess for the geographic position
of the slide.
In addition, DWR is interested in writing image understanding
programs that will inspect an image and ascertain attributes of
the image. In fact, one can find sunset in this particular slide
library by looking for orange at the top of the picture. Low
water in a reservoir entails looking for a blue object surrounded
by a brown ring. Many attributes of a picture in which DWR has
an interest can be found using fairly mundane pattern matching
techniques. Of course, some attributes are much more difficult,
such as ascertaining if the picture contains an endangered species.
These harder attributes will have to wait for future advances
in pattern recognition.
As a result, the schema mentioned above contains a caption field
that is a short document, a picture field that is a Photo-CD image
and a location filed that is of type geographic point. As such,
this application is obviously one on the right hand side of our
matrix.
Moreover, the clients of this data base will all submit ad-hoc
inquiries. One such inquiry would be to find a sunset picture
taken with 20 miles of Sacramento. Clients want a friendly interface
that would assist them is stating the following SQL query:
select id
from slides P, landmarks L S
where sunset (P.picture) and
contains (P.caption, L.name) and
L.location |20| S.location and
S.name = 'Sacramento';
This query can be explained be talking through it from bottom
to top. First, we need to find Sacramento in the Landmarks table.
This yields the geographic location of Sacramento (which is on
several topographic maps). Then, we find other landmarks (L.location)
which are within 20 miles of S.location. |20| is
a user defined operator defined for two operands, each of type
point, that returns true if the two points are within 20 miles
of each other. This is the set of landmarks which we can use
to ascertain if any appear in a caption of a picture. Contains
is a user defined function which accepts two arguments, a document
and a keyword, and ascertains if the keyword appears in the document.
This yields the set of pictures that are candidates for the result
of the query. Lastly, sunset is a second user-defined function
that examines the bits in an image to see if they have orange
at the top. The net result of the query is the one desired by
the client.
Obviously, this application entails "query mostly" on
complex data. As such, it is an example of an upper right corner
application. We now turn to the query language, tools, performance,
and security requirement of this kind of application.
Query Language: Notice in the example query about Sacramento
sunsets, there are four clauses in the predicate of the query.
The first contains a user-defined function, sunset, and is thereby
not in SQL-92. The second clause likewise contains a user-defined
function contains. The third clause contains a user-defined operator,
|20|, which is not in SQL-92. Only the last clause is
expressible in SQL-92. As such, this upper right hand corner
requires a query language that allows at least user-defined functions
and operators. The first standard version of SQL with these capabilities
is SQL-3, now in draft form. Hence, the user requires a SQL-3
DBMS. Any SQL-2 DBMS is essentially useless on this application,
because three of the four clauses cannot be expressed in SQL-2.
Tools: One would like to program the user's application
by displaying on the screen a map of the state of California.
Then, the user could circle with a pointing device the area of
the state in which he was interested. On output, he would like
to see a map of Sacramento County with a "thumbnail"
of each image positioned at its geographic location. With the
ability to "pan" over the county, he could examine thumbnails
of interest. In addition, he would then like the capability to
"zoom" into given areas to obtain the higher resolution
images stored in Photo-CD objects. Such a "pan and zoom"
interface is typical of scientific visualization products such
as Khoros, Explorer and AVS. As such, the user would like a visualization
system carefully integrated with his DBMS. Notice that a standard
4GL is nearly useless on this application; there is not a business
form in sight.
Performance: The user requires that queries such as the
Sacramento sunset one perform very rapidly. These are typically
decision support queries with significant predicates in them.
To perform well in this environment, a collection of optimizations
are required. For example, the sunset function typically will
consume 100 million or more instructions. As such, it the query
optimizer ever sees a clause of the form:
where sunset (image) and date < "Jan 1, 1985"
it should perform the second clause first, thereby eliminating
some of the images. Only if there is nothing else to do should
the sunset clause be evaluated. Being smart about functions which
are expensive to compute is a requirement in the upper left hand
corner. Moreover, if many queries use the sunset function, then
it will be desirable to precompute its value for every image.
Hence, one would execute the function once per image in the database,
rather than once per query wanting sunsets. Automatically supporting
precomputation on image insertions and updates is a very useful
optimization tactic. Lastly, in order to find the landmarks with
20 miles of Sacramento, we need to execute efficiently a "point
in circle" query. Such two dimensional queries cannot be
accelerated by B-tree indexes, which are one-dimensional access
methods. As such, traditional access methods (B-trees and hashing)
are worthless on these sorts of clauses. To accelerate such spatial
clauses, one requires a spatial access method, such as a grid
file, R-tree, or K-D-B tree. A DBMS must either have such "object-specific
access methods" or it must allow a sufficiently wise user or system
integrator to add an access method. Obviously, the best technical answer
is the latter choice.
Notice that optimizing TPC-A is irrelevant to this application
are. There are essentially no transaction processing applications
in the upper right hand corner.
Security: Some upper right hand corner applications have
a need for security. As a result, the DBMS should run in a client-server
architecture as noted in Figure 1. Security is rarely tradable
for performance in this environment. Moreover, since this is
a query world, the commands are very "heavy", and the
performance win to relinquishing security is much less dramatic
than in the lower right hand corner.
We will term DBMSs that support a dialect of SQL-3, that include
non-traditional tools, and which optimize for complex decision
support SQL-3 queries, as Object-Relational DBMSs. They
are relational in nature because they support SQL; they are object-oriented
in nature because they support complex data. In essence they
are a marriage of the SQL from the relational world and the modeling
primitives from the object world. Vendors of Object-Relational DBMSs
include Illustra, UNISQL, and Hewlett-Packard (with their Odaptor for
Allbase and more recently for Oracle).
We have already noted that a SQL-92 system will "lay an egg"
on an upper right hand corner problem, because SQL-92 cannot express
the user's queries. As a result, they must be executed in a user
program, thereby generating a lot of work for the user to do.
In addition, if sunset is executed in user space, then a very
large image will be transmitted over a client-server connection
from server space to client space. This will cause a severe performance
problem. As such, a RelationalDBMS will be painful and slow on
upper right hand corner problems.
Similarly, a persistent language does not have a query language
able to express the user's query. Hence, he must express his query
as a C++ program, leading to significant pain and suffering.
If a user has a lower right hand corner problem, then it is foolish
to use a Relational DBMS solve it as noted earlier. SQL is the
wrong kind of interface. Likewise, one is foolish to use a SQL-3
system for the same reasons. As such, do not use an Object-Relational
DBMS on an lower right hand corner problem.
Lastly, if one has an upper left hand corner problem, then one
can certainly use an Object-Relational DBMS to solve it. Similarly,
SQL-3 is a superset of SQL-92, so one can use an Object-Relational
DBMS to solve a SQL-92 problem. However, object-relational engines
has tended not to be optimized for transaction processing applications.
As such, expect TPC-A to run slower on object-relational engines,
perhaps by as much as a factor of 2. As such, object-relational
engines are not well suited to upper left hand corner applications.
Summary
As explained above, there are three different kinds of DBMSs,
each with its own focus on a particular segment of the marketplace.
These segments require very different query languages and tools,
and are optimized with different kinds of engine enhancements.
Moreover, the requirements for security differ among the segments.
In effect, each kind of engine has carefully "scoped out"
a segment of the marketplace and then optimized for that segment.
In addition, a DBMS oriented toward a specific segment generally
"lays an egg" on problems in a different segment. As
such, the summary of this section is straightforward:
Classify your problem into one of the four quadrants, and then
use a DBMS optimized for the quadrant.
This advice is summarized in Table 2.
A Classification of DBMS Applications
Table 2
We wish to conclude this paper with a final question, namely:
"how large is the upper right hand corner?". Right
now, the upper right hand corner is largely the domain of start-up
companies whose aggregate revenue is not large. However, the real
question is "how much potential resides in this quadrant?" We give
two different answers to this question.
First, there are a significant number of applications that fit
in this quadrant. These include medical imaging problems, digital
library problems, asset management problems in the entertainment
industry, and most scientific data base problems. Based on these
markets, which historically have used file systems because noting
better was available, we would estimate the market for Object-Relational
DBMS to be of a size intermediate between the Relational DBMS
market and the Object-oriented DBMS market. However, the second
answer is perhaps more indicative.
Our prediction is that many of the applications in the upper left
hand corner will migrate toward the upper right hand corner.
For example, consider a typical insurance company which has a
customer data base and a claims data base, presumably implemented
as traditional business data processing applications in a Relational
DBMS. To this application, an insurance company wants to add
the diagram of each accident site, the scanned image of the police
report, the picture of the dented car, the (latitude, longitude)
of the accident site and the (latitude, longitude) of each customers'
home. Then the company wants to find the 10 most dangerous intersections
in each county and charge each customer a "hazard premium"
if he lives within one mile of such an intersection. Besides
finding high risk customers, the insurance company also wants
to find fraudulent body shops, that charge excessive amounts for
repairs, and has other kinds of decision support in addition.
As such, the typical insurance application will move from being
an upper left hand corner application to an application with both
upper left and upper right components. Simultaneously, the upper
left component will be subject to "technological depreciation".
Specifically, the business data processing load of a typical
upper left hand corner application is going up slowly, perhaps
at 10% per year. The number of customers increases slowly, and
the number of incidents is likewise growing slowly. As such,
the load is increasing rather slowly. At the same time, the cost
of the computers to execute this load is declining. Currently,
the cost of CPU cycles, disk storage, and main memory are decreasing
at almost a factor of 2 per year. As a result, the cost of executing
a given workload is declining at almost a factor of two per year.
This makes the business data processing workload technologically
easier, at almost a factor of two per year. As such, not only
is the application moving to the right, but the upper left hand
corner piece is getting easier.
These two effects will drive applications from upper left to upper
right, thereby increasing over time the size of the Object-Relational
DBMS market. As such it is "the next wave".
|
